Specialized Section
HOW TO CHOOSE A DISK ARRAY – CHAPTER 4
13.11.2015, 14:06
Our dear readers, above all we would like to thank you for your increasing interest, which is an impulse for us to continue in a surely successful series ‘How to choose a disk array’.
Because neither the IT field was spared from marketing of many producers that compete in inventiveness with the goal to creatively disguise quite bad service characteristics of a disk array, in our next chapter we are going to focus on the topic of ‘Storage Performance’.
An important fact is that even a tiny change in the setting of stress test parameters of a disk array may cause a difference in the range of tens and hundredfolds in the measured performance.
HOW TO MEASSURE THE PERFORMANCE OF A DISK ARRAY?
You can use some of the testing programs that create a synthetic workload of a disk array. There is quite a variety – e.g. IOzone, IOmeter, SQLIO and the ones who work in the field of ‘video entertainment’ surely knows also a unique project FIO allowing generating a workload typical for HD-recording applications.
These programs have in common that it is necessary for the test to define the workload parameters. And there are a number of them. Reading or writing/recording, sequential or random operations, sizes of blocks, number of competitive streams and many other. As I mentioned above even tiny changes of parameters may have absolutely different impacts on algorithms of the disk array and the measured results may diametrically vary.
And what’s the conclusion? The single information such as ‘the disk array was able to manage e.g. 50 000 Input/Output operations per second’ does not predicate anything. Under certain test conditions a low-end device from Thai-wan (meant with all respect, many good solutions are created there) can manage such a workload; while using another test parameters a Hi-End models of many significant producers may have a problem to deal with such a workload (and they will have to help themselves by using SSD disks).
A way to regularize the comparing of disk arrays is standardization of the test conditions. A creditable work is the activity of organization called Storage Performance Council, who created so called SPC standards for testing of disk arrays.
STORAGE PERFORMANCE COUNCIL
You can find the official website here www.storageperformance.org. There is a unified and fair testing of performance of the disk systems.
The trustworthiness and fair play of SPC program is fulfilled by the fact that the measured results must be accepted by all members of SPC council, who are almost all producers of disk systems. The outcome of each SPC testing is a paper summarizing the basic facts about tested configuration and its results.
The tests are standardized and that way the equity is guaranteed. SPC-1 test focuses on transaction speeds – IOPs. SPC-2 test focuses on transfer speed or permeability of disk systems – MB/s.
In common data centre apps and thanks to server virtualization random operations definitely dominate. That is why it makes sense to focus on SPC-1 tests. May the video entertainment colleagues excuse us, we are going to talk about SPC-2 tests some other time.
HOW DOES SPC-1 TEST WORK?
The test principle is based on simulation of a typical running in data centres – it means imitation of service of database systems, user data and logging. These three services are realized with so called ‘ASU Workers’ which is simply a workload generator of the specific parameters. Each of ASU Workers works with a certain number of competitive streams so the resultant of all those workloads corresponds with the data centre reality as well as possible.
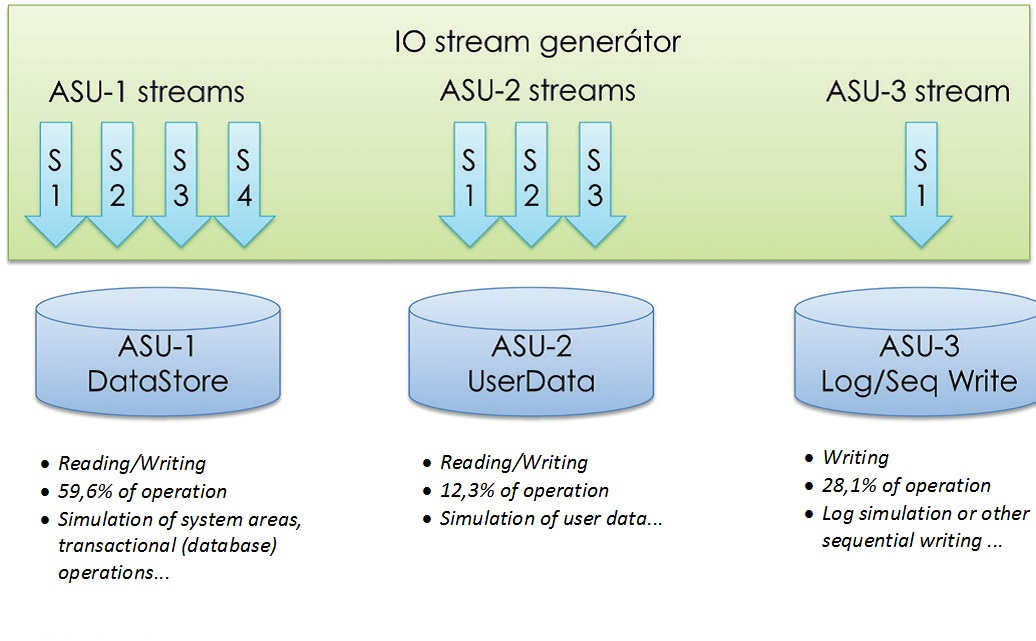
You can find some performance tests of many producers on the website mentioned above. The unified methodology of testing has reduced the options of producers to set the parameters made-to-measure so they would obtain excellent but in the real world unrealistic results.
The space of producers for marketing tricks was narrowed thanks to the SPC tests but some aces up their sleeves still left. That is because the SPC tests were designed before the coming up of many new technologies which’s specific characteristics are not completely reflected;
For example the coming of storage systems based on Intel architecture and embedded Linux/Unix operating systems that are typical for their exponential internal overhead growth with capacitive filling over 60 % or the instability of SSD performance caused by their complicated recording algorithms. In those cases the producers tries to reduce the test length or to test only a part of the available capacity so the product parameters end up in a better light. Nevertheless we are not going to discuss these tricks right now, let’s go back to the disk array performance.
WHAT DOES SPC-1 TEST PREDICATE?
The results of SPC tests predicate the performance potential of a disk array, but providing an adequate number of disks. That is why configurations of disk systems in SPC tests are usually close to the maximum number of disks. Essentially –
The performance of a whole depends on manager (controller) performance and on operator (disk) performance.
But the number of disks is usually at the limits of the disk array. The performance potential of controllers is limited by performance of disk sources. The key for setting a performance potential is the examination of all aspects.
IT’S NOT ONLY ABOUT QUANTITY!
The result of SPC tests is an extensive paper, which beside quantity (how many IOPs the disk array managed) deals with another and often neglected aspect. And that is the quality of service or with what response time this performance was achieved. The performance of applications, databases and so on does not depend only on the peak of IOPs but also on its reaction time of servicing those IO operations.
And here many producers start to differ. Especially the systems that are internally complicated, e.g. above mentioned software defined disk arrays will tell that the response time extremely rise with the workload, which is caused by the high-level internal overhead.
There is a habit that the usable latency of a disk array is up to 5 ms. When it’s higher, it has always an impact on the apps. That’s why it is recommended to take into account not only the number of IOPs but also the number of IO operations managed up to 5 ms while examining the SPC test results. Many SPC benchmarks would appear differently because the actual performance, during which the latency was still bearable, would be significantly lower.
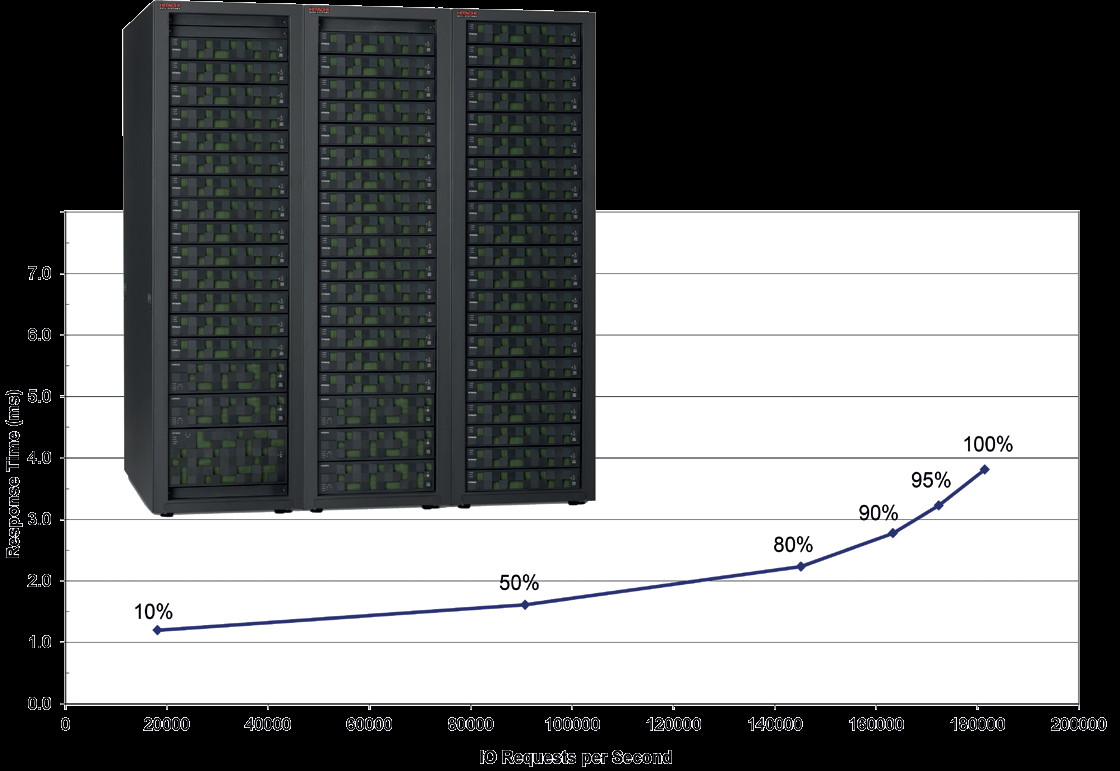
Let’s take a look at the example of SPC benchmark for Hitachi HUS-VM disk system. It is a testing of configuration with ‘rotary’ disks.
The graph shows that the system was able to manage c. 181 000 IOPs and all these operations were managed deep under the limit of 5 ms. That disk system will work correctly and predictably in the data centre. By the way the HUS-VM full-flash configuration reached the efficiency of 300 000 IOPs while 100 % of operations were managed under 1 ms, which is a result that full-flash system producers are not commonly able to reach.
In the next chapter we are going to answer a seemingly simple question: what is more efficient – RAID 5 or RAID 10?
We are looking forward to your suggestions.