Specialized Section
TIERING IN A DISK ARRAY
23.11.2015, 10:30
Tier storage device may be taken as a system which can tell the level of using all sorts of data and assigns them to different types of devices of different performance and price. The purpose is to gain the best from disk devices – the performance from SSDs and reasonable price per unit of stored capacity from classic disks.
Disk array does not work with files but with blocks of data. A file is created out of the blocks at the level of operating system – i.e. the well known NTFS. Nevertheless so the disk array can decide where to store the data it does not need the information from file system.
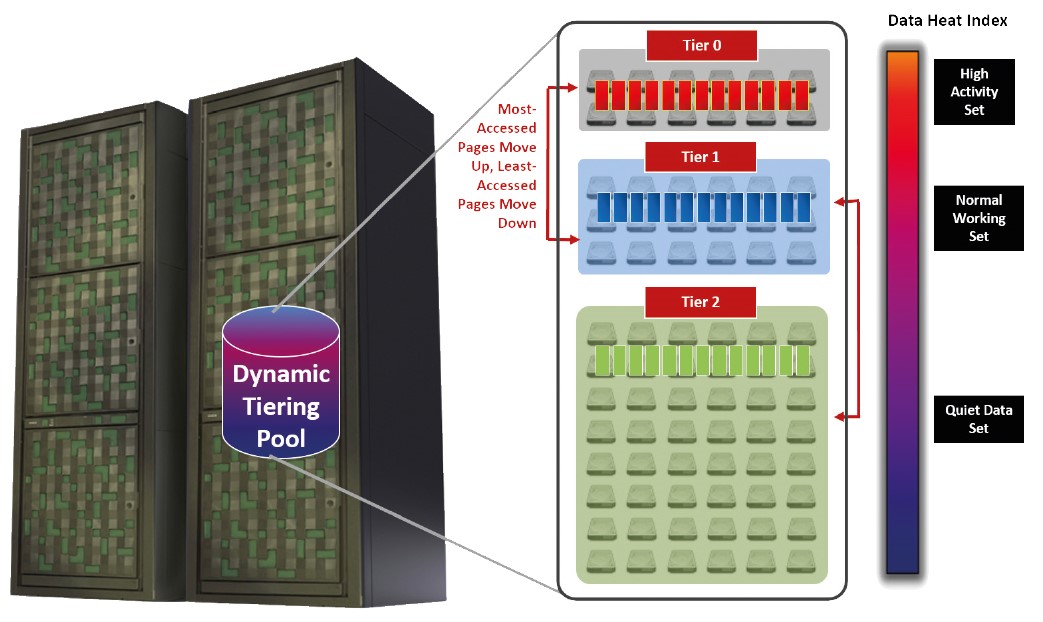
The key used for deciding where to store data is so called “Heat Index”.
The disk array monitors, how often the servers access individual data blocks. Often used blocks – High Activity Sets are reallocated to fast devices and less used blocks – Quiet Data Sets are reallocated for example to NL-SAS disks. Everything is transparent from the view of server. The server cannot “see” on which devices the disk array keeps data.
Because of working on block level, not file level, sometimes from the view of server parts of a single file may be located on different devices. This happens commonly.
For example the extensive database files of ERP system. It is likely that the most often used parts of database are related to up-to-date financial year. The more we dig into history, the more frequency of data usage will drop. In this case the tiering and some SSD/Flash may essentially improve performance potential of a disk array.
WHEN DOES TIERING NOT WORK?
Tiering itself cannot perform miracles and cannot speed up a disk array. It can only find the most efficient locating of data on the base of how often data are worked with. At the same time it is its Achilles’ heel. So tiering can optimize something, there must be data that are used more often than other data.
But what happens when all data are used equally often? For example database of a shop which’s products are accessed by users approximately equally often. Fast Cache or Automatic Tiering, in both cases the algorithm of a disk array will be baffled.
That is why hypothesis “our system will be more efficient because there are SSDs” is not completely correct. It is a marketing shortage, which does not apply to all circumstances.
VULNERABILITY OF TIERING – BACKUP
There are situations when the servers’ service can confuse FastCache or Tiering. That way some data may ”bubble up” to efficient and expensive devices even though it shouldn’t be there.
The service operation is a typical situation. It is primarily the night processes such as backup and also software synchronising or replication. It is an advantage when it is possible to set in Bering politics at some time zones to forbid the servers to influence tiering functioning.
WORKADAY EXAMPLE
The following example describes a situation from a middle-sized corporation. There are used HUS 130 disk array and three physical servers with VMware virtualization. Inside of the virtual environment there are running more than tens of servers performing common corporate tasks – economical systems, information systems, attendance systems, post systems, CIFS sharing and others. All these systems require number of databases such as MS SQL, MS Exchange as post system in this case. Tier pool is compound of 1,4 TiB SSD capacity and 14,4 TiB capacity on 18 x 900 GB 10krpm disks. This company creates average operation of 7.000 transactions per second, at peak hours over 20 000 IOPs.
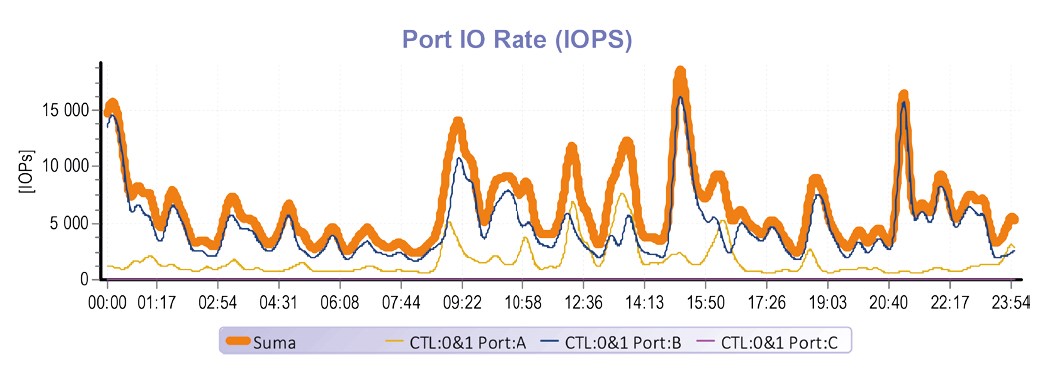
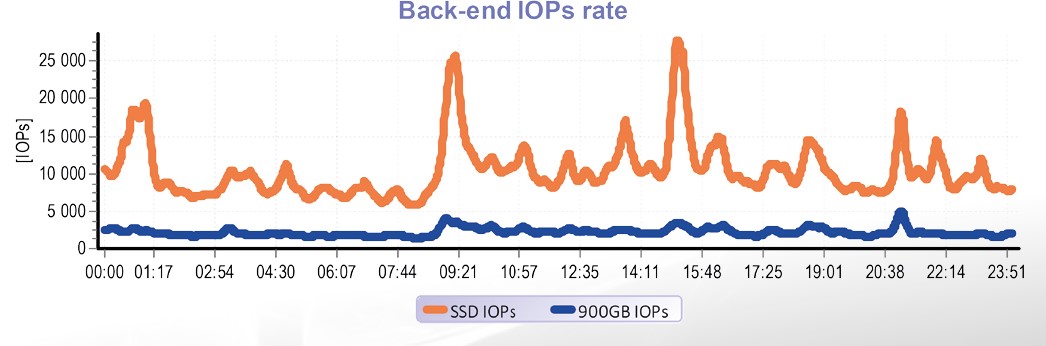
In this specific case the tiering worked very convincingly. Even relatively small amount of SSD capacity in conjunction with an intelligent tiering algorithm managed to sort out 82 % of all operation caused by many servers.
CONCLUSION
In the above described example only 4 % of SSD capacity managed to serve 82 % of operation. Automatic tiering fully met the expectations.
But it is necessary to realize that this conclusion cannot be generalized to all cases. High efficiency of tiering is caused by nature of number of applications run above disk array. The post server and shared network attached storage allocate significant part of capacity – it means applications that are typical for working dominantly with small amount of up-to-date data. And it is this nature of operation that allows tiering to be very efficient.