Sekcja specjalistyczna
JAK WYBRAĆ MACIERZ – część 5
02.12.2015, 10:24
Co ma większą wydajność RAID 5 albo RAID 10? Pozornie proste pytanie, na które się nasuwa odpowiedź „RAID 10“. Aczkolwiek tej sytuacji nie można w ten sposób upraszczać a potencjał wydajności RAID 10 w porównaniu z RAID 5 nie musi być zawsze zauważalny.
Wydajność macierzy jest mierzona w IOPs, czyli ilości operacji wejścia-wyjścia (Input/Output) za sekundę. Jeden wymóg na odczyt lub jeden wymóg na zapis = 1 I/O. Każdy dysk wykorzystany w macierzy posiada określony potencjał wydajności zależny od prędkości obrotowej oraz prędkości przesuwu głowic dysku. Jeśli chodzi o dyski SSD, tak zależy na konstrukcji układu sterującego SSD komórek i jego zdolności realizować skomplikowane operacje związane z procesami realokacji oraz zmazywania unieważnionych stron.
Później kontrolery przetopią potencjał wydajności dysków na Back-endzie (tj. połączenie między kontrolerami i dyskami) w potencjał wydajności na Front-endzie (tj. połączenie między serwerami i dyskami). Wiadomo, że różne typy RAID oraz obliczanie parzystości obciążą kontrolery w różny sposób.
Drugim faktem jest, że systemy RAID posiadają inne właściwości odczytu a inne zapisu. Jest to spowodowane zapisywaniem parzystości czy mirrorowaniem danych. Ta właściwość się nazywa „RAID Write Penalty“.
RAID WRITE PENALTY – jak mamy zrozumieć tę własność?
Załóżmy, że mamy system RAID z ośmioma 2,5 - calowymi dyskami 600 GB 10krpm. Cały niżej przedstawiony test przebiegał na macierzy Hitachi HUS 130, która w swojej klasie należy do tych z najwyższą wydajnością.
To oznacza, że limity wydajności kontrolerów nie zostaną w pełni zastosowane a przeprowadzone pomiary reprezentują wyłącznie limity dysków. Testowanie było przeprowadzone za pomocą SQLIO.

RAID 10
Raid 10 jest kombinacją dwóch macierzy: RAID 1 lustrzany (Mirroring) i RAID 0, gdzie dane są dzielone na tzw. paski (Stripping). Dyski twarde są dublowane (tworzą je pary, gdzie wewnątrz każdej z nich są dane „lustrzanym odbiciem”). Jeśli dojdzie do awarii dysku twardego, wykorzystuje się kopię z dysku lustrzanego.
Nasza konfiguracja testowa RAID 10, którą wybraliśmy, składa się z ośmiu dysków a jest zorganizowana jako 4+4. Dla kontrolera są obliczenia RAID 10 bardzo proste, wystarczy dane zapisać dwukrotnie i nie trzeba obliczać żadnego skomplikowanego systemu parzystości. Niestety gorzej to wygląda z efektywnością pojemności, gdzie jest potrzeba podwójnej pojemności na dyskach, aby osiągnąć wymaganą pojemność. Ale nas interesuje aspekt wydajności.
Z punktu widzenia odczytu są w jednym kroku odczytane dane ze wszystkich ośmiu dysków. Więc wydajność odczytu będzie wynosić 8 razy wydajność naszego jednego dysku (2,5“ SAS – około 180-240 IOPs). Pomiar stress testem SQLIO pokazał 1760 IOPs. Ale odmienna sytuacja dotyczy zapisu. Kontroler zapisuje prymarne dane na połowie dysków, co w naszym przypadku stanowi 4, a na drugiej połowie dysków zapisuje ich kopię. Więc wydajność zapisu będzie wynosić 4 razy wydajność jednego dysku.
Z tego wynika, że w RAID 10 jest odczyt dwukrotnie szybszy od zapisu. A właśnie ta własność jest związana z tym, co się nazywa„RAID Write Penalty“. W tym przypadku Write Penalty = 2. W naszej sytuacji pomiar wydajności zapisu wyniósł 1096 IOPs.
Workload RAID 10 Wydajność Random Read, 8kB Blok 4+4 1760 IOPs Random Write, 8kB Blok 4+4 1096 IOPs
RAID 5
RAID 5 podobnie jako RAID 0 wykorzystuje dzielenie danych na paski (Stripping), z tą różnicą że dodatkowo obliczane są dane parzystości. Wartość parzystości jest obliczana z dysków danych za pomocą logicznego operatora XOR. Parzystość jest wskutek wydajności dystrybuowana na wszystkie dyski i jest wykorzystywana w przypadku awarii dysku w celu rekonstrukcji danych. Po prostu weźmiemy wartość parzystości, aby dokonać XOR operacji z pozostałymi dyskami danych a tym się zrekonstruują dane, które były zapisane na wadliwym dysku.
W celu relewantnego porównania również i w tym przypadku RAID będzie posiadał 8 dysków, ale zorganizowanych jako 7 + 1.
Z punktu widzenia odczytu RAID 5 wykorzysta wszystkie dyski – podobnie jak RAID 10. To znaczy, że potencjał wydajności będzie podobny.
Jeśli chodzi o zapis, tak sytuacja jest diametralnie inna. Kontroler musi podjąć następujące kroki:
1) Przeczytać pierwotne dane
2) Przeczytać parzystość
3) Zapisać nowe dane
4) Zapisać nową parzystość
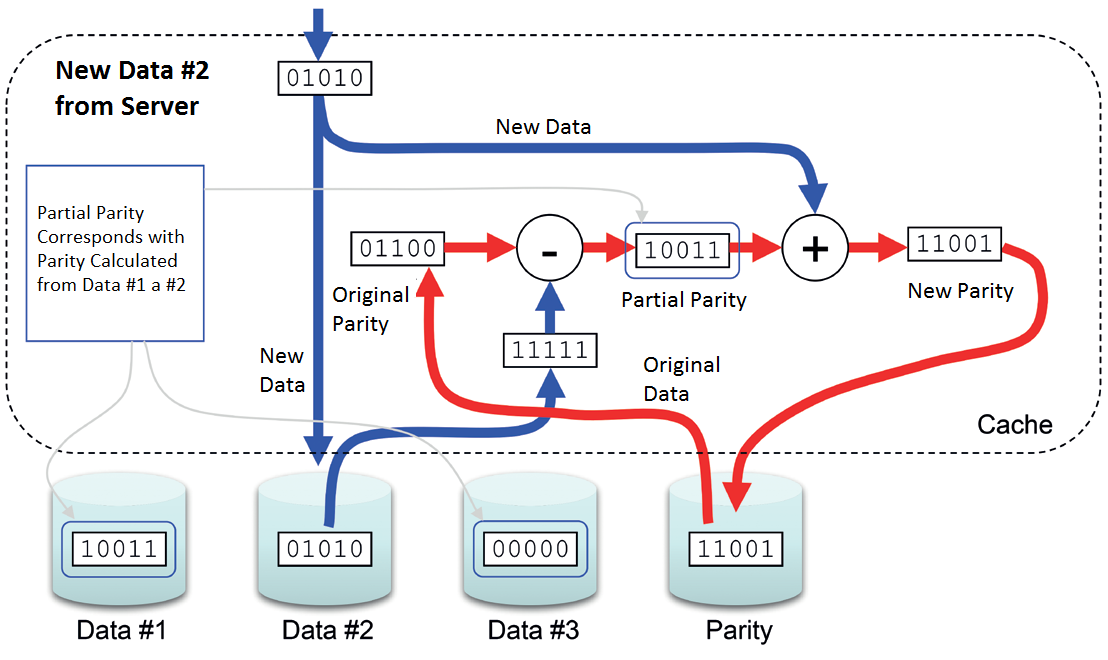
W tym przypadku Write Penalty = 4. To oznacza dwa razy tyle, co miał RAID 10, a to jest też powód, dla którego RAID 5 nie jest idealnym rozwiązaniem, jeśli chodzi o sytuacje, gdzie przeważają przypadkowe zapisy.
Dla odczytu było w praktycznych testach zmierzono 1710 IOPs. Zapis, który był obciążony Write Penalty = 4, osiągnął wydajność 489 IOPs.
Workload RAID 5 Wydajność Random Read, 8kB Blok 7+1 1710 IOPs
Random Write, 8kB Blok 7+1 489 IOPs
Spójrzmy bardziej szczegółowo na pomiary danych z punktu widzenia rzeczywistej analizy wewnętrznych operacji w ramach macierzy HITACHI HUS 130.
Ta macierz umożliwia monitorować stosunek wydajności na setkach perymetrów wewnątrz jego architektury. W ten sposób mamy możliwość analizować wszystkie procesy, które się odbywają wewnątrz kontrolerów macierzy. Jednak dla tej sytuacji wystarczy nam pokazanie działania w obszarze Front-endu (IOPs na portach macierzy) oraz działania w obszarze Back-endu (IOPs na dyskach).
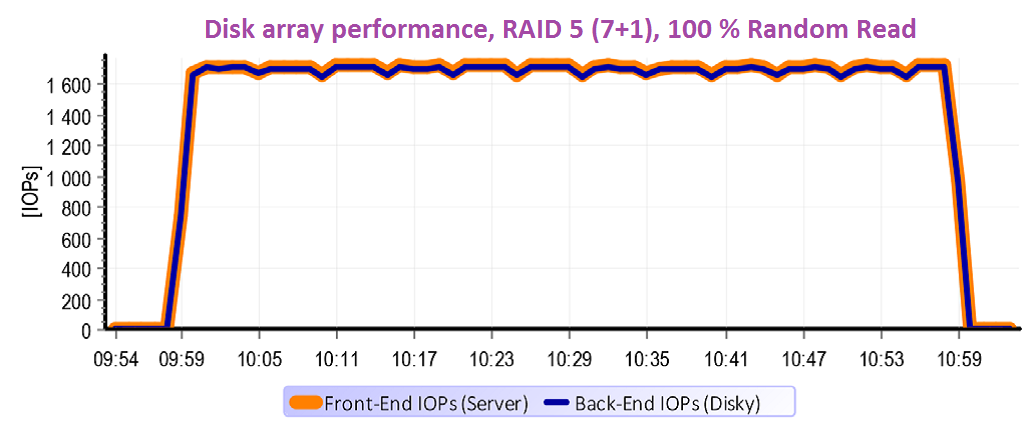
Powyższy wykres przedstawia właściwości RAID 5 dla odczytu. Macierzy niczego nie ułatwialiśmy. Przeprowadziliśmy testy na 100% przypadkowych operacji o pojemności 2 x 500 GB. Pojemność, którą testowaliśmy wielokrotnie przekroczyła wielkość cache macierzy (32 GB), w związku z tym cache właściwie nie znalazła zastosowania. Innymi słowy – po wszystko, co chciał serwer odczytać, kontroler musiał sięgnąć na dyski. Procesy z Front-endu się zatem przesunęły do Back-endu w stosunku 1:1.
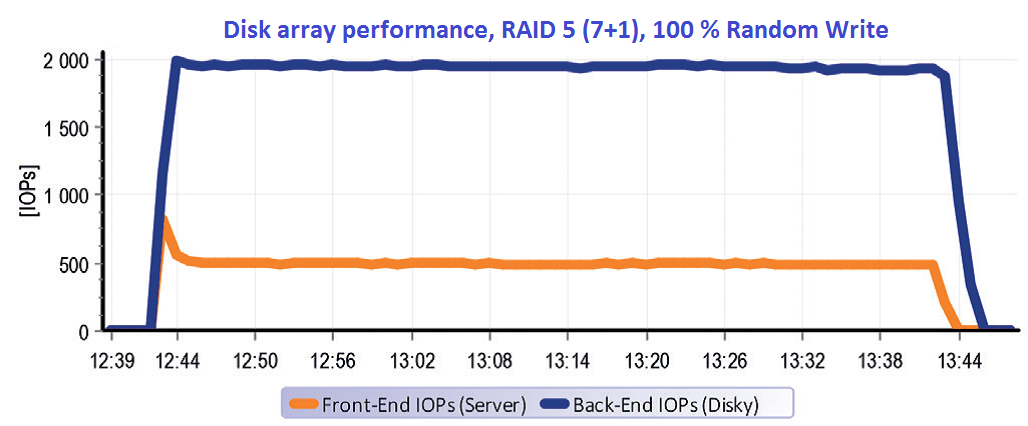
Całkowicie inna sytuacja nastanie dla RAID 5 w przypadku zapisu. Na wykresiemożemy jasno widzieć, że procesy od serwerów na granicy około 500 IOPs spowodowały na dyskach procesy niemal 2000 IOPs.
A to oznacza Write Penalty = 4. Godne uwagi jest parę minut na początku testu, gdzie się pojawia kulminacja wydajności spowodowana pustą cache, która szybko przyjmie pierwszą minutę procesu. Potem się cache zapełni a biorąc pod uwagę charakter przypadkowych operacji, tak wydajność już nie akceleruje a dane przez nią tylko „przeciekają”. Na końcu testu znowu możemy zauważyć, że proces na dyskach trwa a to nawet po skończeniu procesów na serwerach – destage cache.
RAID 6
RAID 6 jest rozbudowaną formą macierzy RAID 5, z tą różnicą, że zamiast wbudowanego dysku zapasowego, macierz poziomu szóstego posiada zdublowaną parzystość. Jego rozwój nie mógł się obejść bez nadejścia wysokopojemnościowych dysków SATA i NL-SAS. Kiedy pojawi się jakaś awaria, tak rekonstrukcja parzystości w przypadku tych dysków może trwać nawet kilka dni. Jeśli by szło o RAID 5, tak w trakcie tej awarii grupa dysków by została bez zabezpieczenia, a awaria kolejnego dysku oznacza stratę danych. W związku z tym RAID 5 został uzupełniony kolejnym streamem parzystości a to tak, aby grupa dysków była odporna na awarię i dwóch dysków jednocześnie.
Ponownie wróćmy do naszej macierzy RAID złożonej znowu z ośmiu dysków. W przypadku RAID 6 dyski będą zorganizowane jako 6 + 2. Z punktu widzenia odczytu się tego zbyt wiele nie zmieni, kontroler ponownie może sięgnąć po dane do wszystkich dysków jednocześnie a tak wydajność odczytu jest podobna jako w RAID 5.
Jeśli chodzi o zapis, tak mamy tutaj w odróżnieniu od RAID 5 kolejne dodatkowe dwie operacje. Jest konieczne przeczytać również drugi stream parzystości oraz i ten musimy zapisać. Write Penalty dla RAID 6 = 6.
Oczywiście, że wpływ na wydajność zapisu jest wielki, dlatego nasadzanie RAID 6 ma sens jedynie tam, gdzie spełnia swoje zadanie – tj. dla ochrony bloków parzystości złożonych z dysków pojemnościowych.
Workload RAID 6 Wydajność
Random Read, 8kB Blok 6+2 1472 IOPs
Random Write, 8kB Blok 6+2 255 IOPs
CZY RAID PENALTY MA ZAWSZE SWOJE ZASTOSOWANIE?
Producenci macierzy bardzo dobrze sobie zdają sprawę, że RAID Penalty powoduje fundamentalny spadek wydajności operacji zapisu. Dlatego algorytmy kontrolerów macierzy są tak optymalizowane, aby jeśli to jest tylko chociaż trochę możliwe, RAID Penalty nie była zastosowana.
Na przykład, jeśli serwer komunikuje z macierzą poprzez operacje sekwencyjne, to logika macierzy reaguje na to w ten sposób, że spróbuje zestawić cały blok danych w cache. Jeśli się jej to uda, obliczy dla niej parzystość a cały blok zapisze naraz na dysk, bez tego, aby się musiał zajmować tym, jaka była pierwotna parzystość oraz pierwotne dane i musiał je odczytywać z dysków.
Jeśli firmware macierzy jest naprawdę dobrze napisany, uruchomi jeszcze jedną optymalizację. O ile rozpozna, że serwer żąda od macierzy sekwencyjnego odczytu, odczyta sobie kolejne dane do cache. Ta oto technologia nosi nazwę read-ahead.
Jeżeli macierz rozpozna zapis sekwencyjny, nie zapisuje go natychmiast, ale wręcz odwrotnie, stara się zestawić z małych przychodzących bloków jeden wielki, który następnie odeśle na dysk.
I tak w praktyce w przypadku operacji sekwencyjnych dochodzi do interesującego efektu. Podczas gdy na portach macierzy może dojść do burzy dziesiątek tysięcy IOPs, tak między kontrolerami i dyskami może ich być sporadycznych parę tysięcy. Wymownie to przedstawia praktyczny pomiar.
Wróćmy z powrotem do naszego RAID 5 złożonego z ośmiu dysków SAS 2,5“ 600 GB 10 krpm.
Dla przypadkowych operacji zmierzono potencjał wydajności na niecałe 2000 IOPs dla odczytu a w przybliżeniu ćwierć dla zapisu. Jednak co się stanie, jeżeli dokonamy „drobnej” zmiany – zmienimy ustawienia testującego programu SQLIO z random na operacje sekwencyjne?
Graf dokumentuje, w jaki sposób firmware macierzy optymalizuje przetworzenie operacji sekwencyjnych. Małe bloki sekwencyjne posłane serwerem, są ułożone w cache w wielkich blokach. Później do dysków odchodzi istotnie mniejsza ilość, ale o to większych IOPs. We wyżej wspomnianym przypadku zostało zmierzonych 50 000 IOPs na front-endzie, podczas gdy procesy na dyskach pokazywały jedynie 2 000 IOPs.
TEST S 200 DYSKAMI
Na wstępie zostało postawione pytanie, co jest szybsze RAID 5 albo RAID 10. Pytanie zostało bez odpowiedzi, ponieważ nie istnieje żadna uniwersalna odpowiedź – zawsze zależy na właściwości workloadu, który się nad daną grupą planuje. W naszym praktycznym teście wykorzystano 25 grup dysków zorganizowanych w pierwszym przypadku jako RAID 10 (4+4), w drugim jako RAID 5 (7+1).
Stress testu dokonano za pomocą programu SQLIO na 25 konkurencyjnych streamach.
Abyśmy respektowali realne zachowanie aplikacji, test się odbywał na blokach 8 kB dla operacji przypadkowych a blokach 64 kB dla operacji sekwencyjnych.
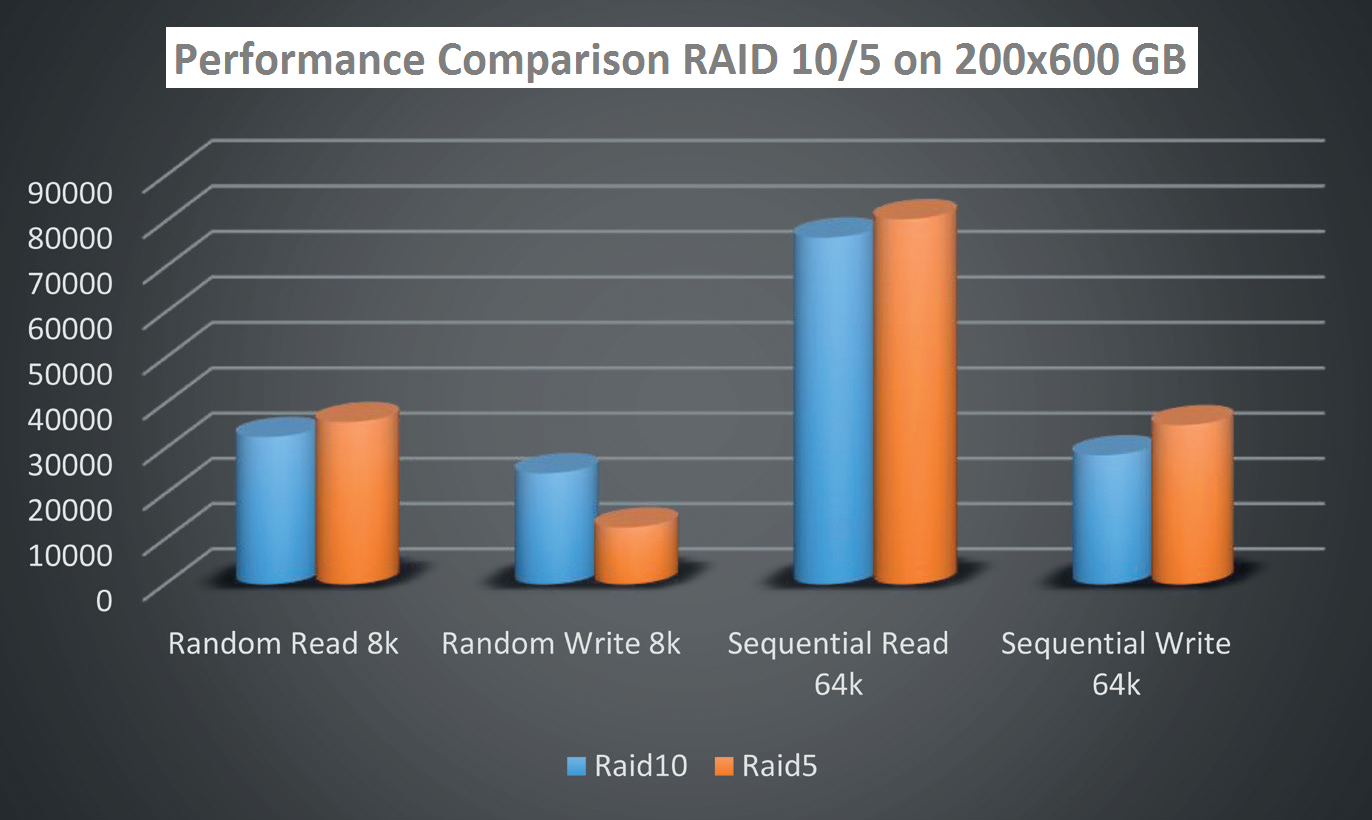
Zmierzone wyniki pokazały, że najmocniejszą stroną RAID 10 są zapisy w operacjach przypadkowych. Natomiast RAID 5 jest idealnym systemem parzystości dla operacji sekwencyjnych.
Dlatego producenci baz danych, jak np. Microsoft, w swoich najlepszych praktykach („best practicies“) dla SQL w jasny sposób przedstawiają zalecenie do konfiguracji dyskowych narzędzi. Istotą tej idei jest sekcja działalności baz danych (który w typowy sposób komunikuje w przypadkowych małych blokach) oraz redo log działalności (który w typowy sposób komunikuje w wielkich blokach zapisu).
Jak z powyższego grafu możemy poznać, jest wprost oczywiste, że dla bazy danych jest idealny RAID 10, natomiast dla redo logów RAID 5.
Sekcja baz danych i logów ma jeszcze jeden pozytywny wpływ – nad jednym LUNem się macierzy nie mieszają dwa całkiem inne typy działania. Potem algorytmy cache są w stanie się bardziej efektywnie adaptować a ten aspekt ma pozytywny wpływ na wydajność.
PODSUMOWUJĄC?
Badania zwróciły uwagę na wielki wpływ wymagań testu na zmierzoną wydajność macierzy.
Nasz modelowy przykład z ośmioma dyskami SAS miał potencjał wydajności w szeregu setek aż tysięcy transakcji dla przypadkowych operacji. Dokładna liczba zależy od typu RAID oraz faktu, jeśli chodzi o odczyt czy zapis. W odróżnieniu od tego sekwencyjny odczyt lub zapis jest w stanie bardzo skutecznie akcelerować algorytm macierzy a różnice w odróżnieniu od przypadkowego działania nie są w setkach procent, ale bardziej prawdopodobnie w tysiącach procent. Tutaj bym znowu chciał powrócić praktycznej strony wyboru macierzy z punktu widzenia zleceniodawcy. Jak było pokazane, ustawieniem wymogów testu można przy niej i samej konfiguracji osiągnąć – z pewnym stopniem przesady – właściwie dowolnego wyniku.
Jeśli zamawiający nie chce być rozczarowany właściwościami eksploatacji produktu, który wybrał, jest na miejscu rozważyć kilka ważnych kroków:
1) Najlepiej dzięki analizie obecnego środowiska ustalić wymagania odnośnie przyszłego systemu. 2) W odpowiedni sposób ustalić typy RAID z respektowaniem najlepszych praktyk producentów planowanych aplikacji.
3) Rozważyć, jeśli jakaś forma akceleracji za pomocą dysków SSD (Tiering, Fast Cache) spełni oczekiwania a ich znaczny wpływ na cenę się naprawdę opłaci.
4) Zdefiniować, jakim urządzeniem będziemy przeprowadzać akceptacyjną performance test oraz jakie będą parametry tego testu.
Jakkolwiek poszczególne punkty brzmią prosto, za nimi się skrywa stosunkowo głęboka analiza. Do niej jest wymagane szerokie know-how w dziedzinie „storage performance“.
Już tylko pierwszy krok, tj. analiza obecnego działania, skrywa dla architekta rozwiązań storage skomplikowane zadanie – musi dobrze ocenić zmierzone dane. Ilość transakcji, które ustalił monitoring, może mieć dwa powody. Pierwsza możliwość jest, że aplikacja nie generuje więcej transakcji. Druga możliwość jest, że obecne narzędzie zapisu ma limit wydajności a po prostu więcej już „nie puści”. Ta ocena jest możliwa na podstawie analiz latencji oraz długości kolejek i wymaga dostateczną ilość doświadczenia.
Również ocena stosowności nasadzenia SSD akceleracji jest rozdziałem, który wymaga know-how. Sprzedawcę, który nie posiada bazy tej wiedzy, poznacie na podstawie „recytacji” upraszczających marketingowych skrótów bez zrozumienia sedna problemu. Efektywność SSD akceleracji, która połączy potencjał wydajności różnych mediów (SSD, SAS, NL-SAS), jest zawsze adekwatny do stopnia zmienialności danych.
Jeśli w objętości zapisanych danych istnieją dane, których używamy często i odwrotnie „śpiące” dane, później nawet mała ilość SSD pojemności w znaczący sposób zwiększy wydajność, ponieważ macierz potrafi rozpoznać, które bloki danych są używane często a te umieści na najszybsze dyski.
Pomimo to istnieją również sytuacje i aplikacje, które przystąpią na wszystkie zapisane dane prawie tak samo często. Innymi słowy nie istnieją tzw. „Hot Data“, które by macierz mogła uprzywilejować poprzez zapisanie na SSD. W takich przypadkach SSD przyniosą tylko małe zwiększenie wydajności, ale w zamian za to wielkie rozczarowanie wskutek wyżej uczynionej inwestycji.
Ocena zdatności i konfiguracji macierzy tak, aby jej realne nasadzenie spełniało oczekiwania, nie jest w pełni łatwą kwestią oraz wymaga specjalistów.