Odborná sekce
JAK VYBRAT DISKOVÉ POLE – 5. díl
02.12.2015, 10:24
Je výkonnější RAID 5 nebo RAID 10? Zdánlivě jednoduchá otázka s podbízející se odpovědí „RAID 10“. Nicméně situaci nelze takto zjednodušit a výkonnostní potenciál RAID 10 se ve srovnání s RAID 5 nemusí projevit vždy.
Výkon diskového systému je měřen v IOPS neboli počtu Input/Output za sekundu. Jeden požadavek na čtení nebo jeden požadavek na zápis = 1 IO. Každý disk použitý v diskovém poli
má určitý výkonnostní potenciál závisející na rychlosti otáčení a rychlosti seeku hlaviček disku. V případě SSD disků pak na konstrukci řadiče SSD buněk a jeho schopnosti realizovat složité operace spojené s procesy realokací a mazáním zneplatněných stránek.
Controllery pak výkonnostní potenciál disků na backendu (tj. konektivita mezi controllery a disky) přetaví na výkonnostní potenciál na front-endu (tj. konektivita mezi servery a controllery). Je známou věcí, že různé typy RAID a výpočty parity zatíží controllery různým způsobem.
Druhou skutečností je, že RAID systémy mají jiné vlastnosti pro čtení a jiné vlastnosti pro zápis. Je to způsobeno nutností ukládat paritu či zrcadlit data. Tato vlastnost se jmenuje „RAID Write Penalty“.
RAID WRITE PENALTY – jak této vlastnosti rozumět?
Předpokládejme, že máme systém RAID s osmi 2,5“ disky 600 GB 10krpm. Veškeré níže uvedené testování bylo učiněno na diskovém poli Hitachi HUS 130, které ve své třídě patří k výkonnostní špičce.
Výkonnostní limity controllerů se tak zdaleka neuplatní a provedená měření reprezentují pouze limity disků. Testováno bylo nástrojem SQLIO.

RAID 10
Raid 10 je kombinace zrcadlení (mirror) a souběžného zápisu v pruzích (stripe). Pevné disky jsou zde organizovány do párů a uvnitř každého diskového páru jsou data zrcadlena. Dojde-li
k výpadku pevného disku, je použita kopie dat ze zrcadleného disku.
Námi zvolená testovací konfigurace RAID 10 má osm disků a je organizována jako 4+4. Pro controller jsou výpočty RAID 10 velmi jednoduché, prostě se jen data uloží dvakrát a nemusí se počítat žádný složitý paritní systém. Horší je to již s kapacitní efektivitou, kde pro dosažení požadované kapacity je třeba dvojnásobné kapacity na discích. Nás ale zajímá výkonnostní aspekt.
Z hlediska čtení jsou v jednom kroku přečtena data ze všech osmi disků. Výkonnost pro čtení tedy bude 8x výkon našeho jednoho disku (2,5“ SAS – cca 180-240 IOPs). Měření stress testem SQLIO ukázala 1760 IOPs. Rozdílná situace je ale pro zápis. Controller ukládá primární data do poloviny disků, v našem případě čtyř, a do druhé poloviny disku zapisuje jejich kopii. Výkon pro zápis bude tedy 4x výkon jednoho disku.
V případě RAID 10 je tedy čtení dvakrát rychlejší než zápis. A právě tato vlastnost souvisí s tím, co je nazýváno „RAID Write Penalty“. V tomto případě je tedy Write Penalty = 2. V našem případě byl změřen výkon pro zápis 1096 IOPs.
Workload RAID 10 Výkonnost Random Read, 8kB Blok 4+4 1760 IOPs Random Write, 8kB Blok 4+4 1096 IOPs
RAID 5
RAID 5 je kombinací souběžného zápisu v pruzích (stripe) a počítání parity. Hodnota parity se počítá pomocí logického operandu XOR z datových disků. Parita je z výkonnostních důvodů distribuována napříč všemi disky a používá se v případě výpadku disku pro rekonstrukci dat. Jednoduše se vezme hodnota parity a provede se XOR operace se zbylými datovými disky a tím se zrekonstruují data, která byla na vadném disku.
Abychom získali relevantní srovnání, i v tomto případě bude mít RAID skupina 8 disků. V případě RAID 5 bude organizována jako 7+1.
Z hlediska čtení RAID 5 zaměstná všechny disky – podobně jako RAID 10. Výkonnostní potenciál je tedy obdobný.
Pro zápis je však situace diametrálně odlišná. Controller musí učinit následující kroky:
1) Přečíst původní data
2) Přečíst paritu
3) Zapsat nová data
4) Zapsat novou paritu
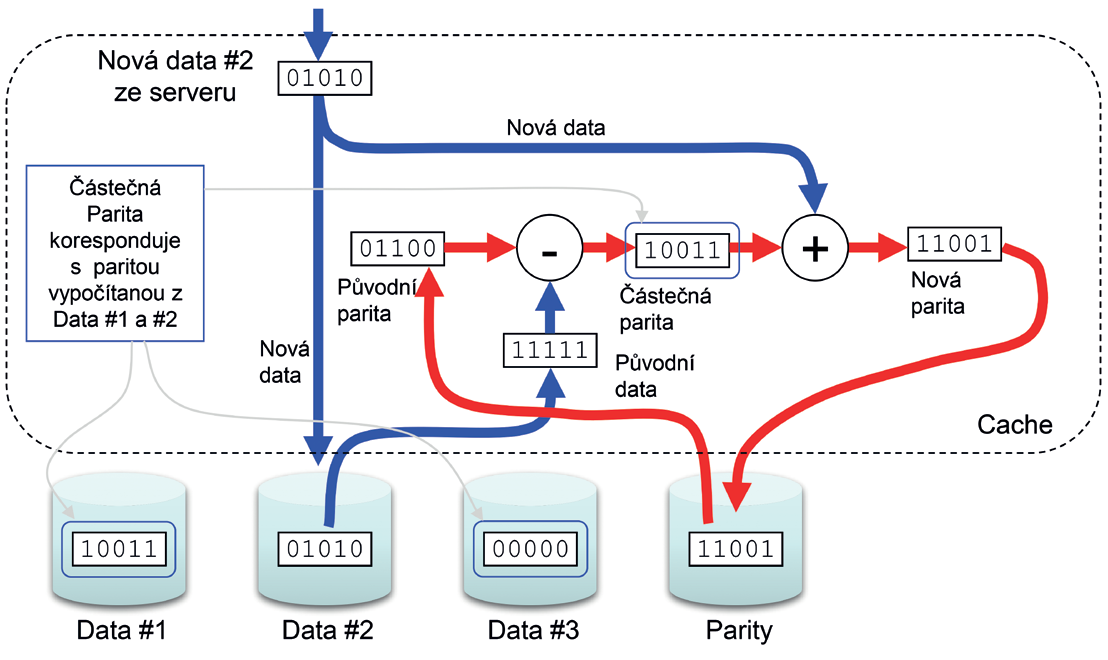
Write Penalta je v tomto případě 4. To je dvojnásobek ve srovnání s RAID 10 a také důvod proč RAID 5 není ideální pro provoz, kde převažují náhodné zápisy.
Pro čtení bylo při praktických testech změřeno 1710 IOPs pro čtení. Zápis, který je zatížen RAID Penaltou = 4, dosáhl výkonu 489 IOPs.
Workload RAID 5 Výkonnost Random Read, 8kB Blok 7+1 1710 IOPs
Random Write, 8kB Blok 7+1 489 IOPs
Podívejme se na změřená data podrobněji pohledem skutečné analýzy interních operací v rámci diskového pole HITACHI HUS 130.
Tento diskový systém umožňuje sledovat výkonnostní poměry na stovkách perimetrů uvnitř jeho architektury. Máme tak možnost do detailu analyzovat všechny děje, které se uvnitř controllerů diskového pole odehrávají. Pro tuto situaci si však vystačíme se zobrazením provozu na front-endu (IOPs na portech diskového pole) a provozu na back-endu (IOPs na discích).
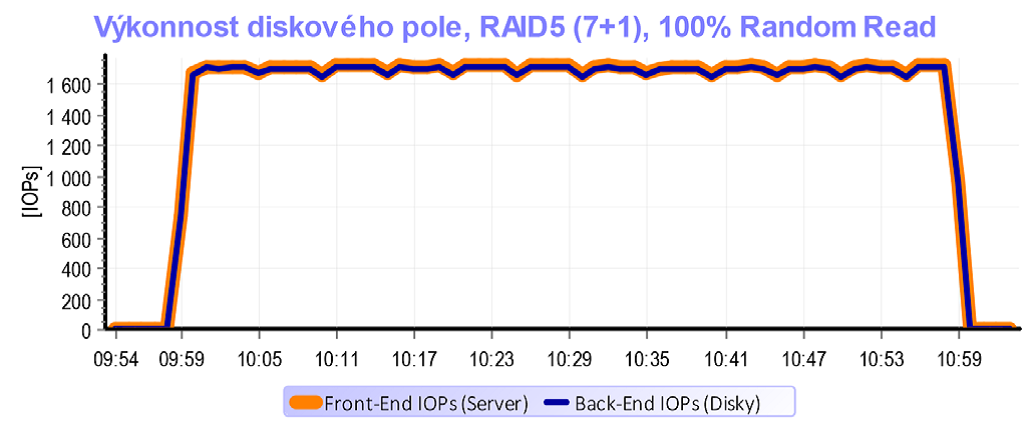
Tento graf zobrazuje vlastnosti RAID 5 pro čtení. Diskovému poli jsme nic neusnadnili. Testovaly se 100% náhodné operace na kapacitě 2 x 500 GB. Testovací kapacita tedy mnohokráte přesáhla velikost cache diskového pole (32 GB) a proto se cache v podstatě neuplatnila. Jinýmy slovy – pro všechno, co chtěl server číst, si musel controller sáhnout na disky. Provoz z front-endu se tedy na back-end překlopil 1:1.
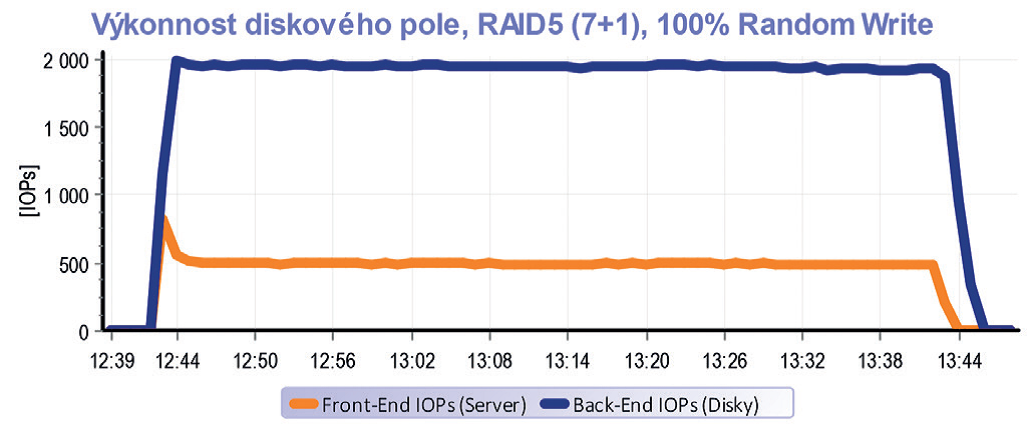
Zcela jiná situace nastane pro RAID 5 v případě zápisu. Z grafu je jasně vidět, že provoz od serverů ve výši cca 500 IOPs způsobil na discích provoz téměř 2000 IOPs.
A to znamená Write Penalty=4. Za zmínku stojí pár minut začátku testu, kde je výkonnostní špička způsobená prázdnou cache, která rychle přijme první minutu provozu. Následně se ale cache zaplní a vzhledem k povaze náhodných operací již výkon neakceleruje a data přes ni pouze „protékají“. Na konci testu je zase patrné, že provoz na discích trvá i po skončení provozu na serverech – destage cache.
RAID 6
RAID 6 je rozšíření paritního systému RAID 5 o další paritní stream. Jeho vývoj si vyžádal příchod vysokokapacitních SATA a NL-SAS disků. Rekonstrukce parity v případě výpadku u těchto disků si vyžádá čas i několik dnů. V případě RAID 5 by po tuto dobu byla disková skupina bez zabezpečení a pád dalšího disku znamená ztrátu dat. Proto se RAID 5 doplnil dalším paritním streamem tak, aby disková skupina byla odolná proti výpadku i dvou disků najednou.
Vraťme se k naší RAID skupině složené opět z osmi disků. V případě RAID 6 bude organizována jako 6+2. Z hlediska čtení se toho příliš nemění, controller si opět může sáhnout pro data do všech disků najednou a tak výkon pro čtení je podobný RAID 5.
V případě zápisu zde však máme oproti RAID 5 další dvě operace navíc. Je třeba přečíst i druhý paritní stream a stejně tak je potřeba jej i uložit. Write Penalty je pro RAID 6 tedy 6.
Dopad do výkonnosti zápisu je samozřejmě velký a proto má smysl RAID 6 nasazovat opravdu jen tam, kde má účel – tj. pro ochranu paritních skupin složených z kapacitních disků.
Workload RAID 6 Výkonnost
Random Read, 8kB Blok 6+2 1472 IOPs
Random Write, 8kB Blok 6+2 255 IOPs
UPLATNÍ SE RAID PENALTA VŽDY?
Výrobci diskových systémů si velmi dobře uvědomují, že RAID Penalta způsobuje zásadní výkonnostní propad write operací. Proto jsou algoritmy controllerů diskových polí optimalizovány
tak, aby pokud je to jen trochu možné, se tato penalta neuplatnila.
Například pokud server komunikuje s diskovým polem v sekvenčních operacích, reaguje na to logika diskového pole tak, že se pokusí sestavit celý blok dat v cache. Pokud se mu to podaří, vypočítá pro něj paritu a celý blok uloží do disků najednou, aniž by se musel zaobírat tím, jaká byla původní parita i původní data a číst je z disků.
Je- li firmware diskového pole opravdu dobře napsán, nasadí ještě jednu optimalizaci. Pokud rozpozná, že server po diskovém poli požaduje sekvenční čtení, předečte si další data do cache. Tato technologie se nazývá read-ahead.
Pokud diskové pole rozpozná sekvenční zápis, neukládá okamžitě a naopak se snaží z malých příchozích bloků sestavit jeden velký, který následně odešle do disků.
V praxi tak v případě sekvenčních operací dochází k zajímavému efektu. Zatímco na portech diskového pole se může odehrávat bouře v podobě desetitisíců IOPs, tak mezi controllery a disky se jich může odehrávat sporadických pár tisíc. Výmluvně to dokresluje praktické měření.
Vraťme se zpět k našemu RAID 5 složenému z osmi SAS 2,5“ disků 600 GB 10 krpm.
Pro náhodné operace byl změřen výkonnostní potenciál necelých 2000 IOPs pro čtení a zhruba čtvrtina pro zápis. Co se však stane, pokud uděláme „drobnou“ změnu – změníme nastavení testovacího programu SQLIO z random na sekvenční operace?
Graf dokumentuje, jakým způsobem firmware diskového pole optimalizuje zpracování sekvenčních operací. Malé sekvenční bloky zaslané serverem jsou v cache složeny do velkých bloků. Do disků pak odchází podstatně menší množství o to větších IOPs. Ve výše uvedeném případě bylo změřeno 50 000 IOPs na front-endu, zatímco provoz na discích byl pouze 2 000 IOPs.
TEST S 200 DISKY
V úvodu byla položena otázka, zda je rychlejší RAID 5 nebo RAID 10. Otázka zůstala nezodpovězena, protože žádná univerzální odpověď neexistuje – vždy záleží na povaze workloadu, který se nad danou skupinou plánuje. V našem praktickém testu bylo použito 25 skupin disků organizovaných v prvním případě jako RAID 10 (4+4), v druhém případě jako RAID 5 (7+1).
Stress test byl prováděn pomocí nástroje SQLIO na pětadvaceti konkurenčních streamech. Abychom respektovali skutečné chování aplikací, byl test prováděn na 8 kB blocích pro náhodné operace a 64 kB blocích pro sekvenční operace.
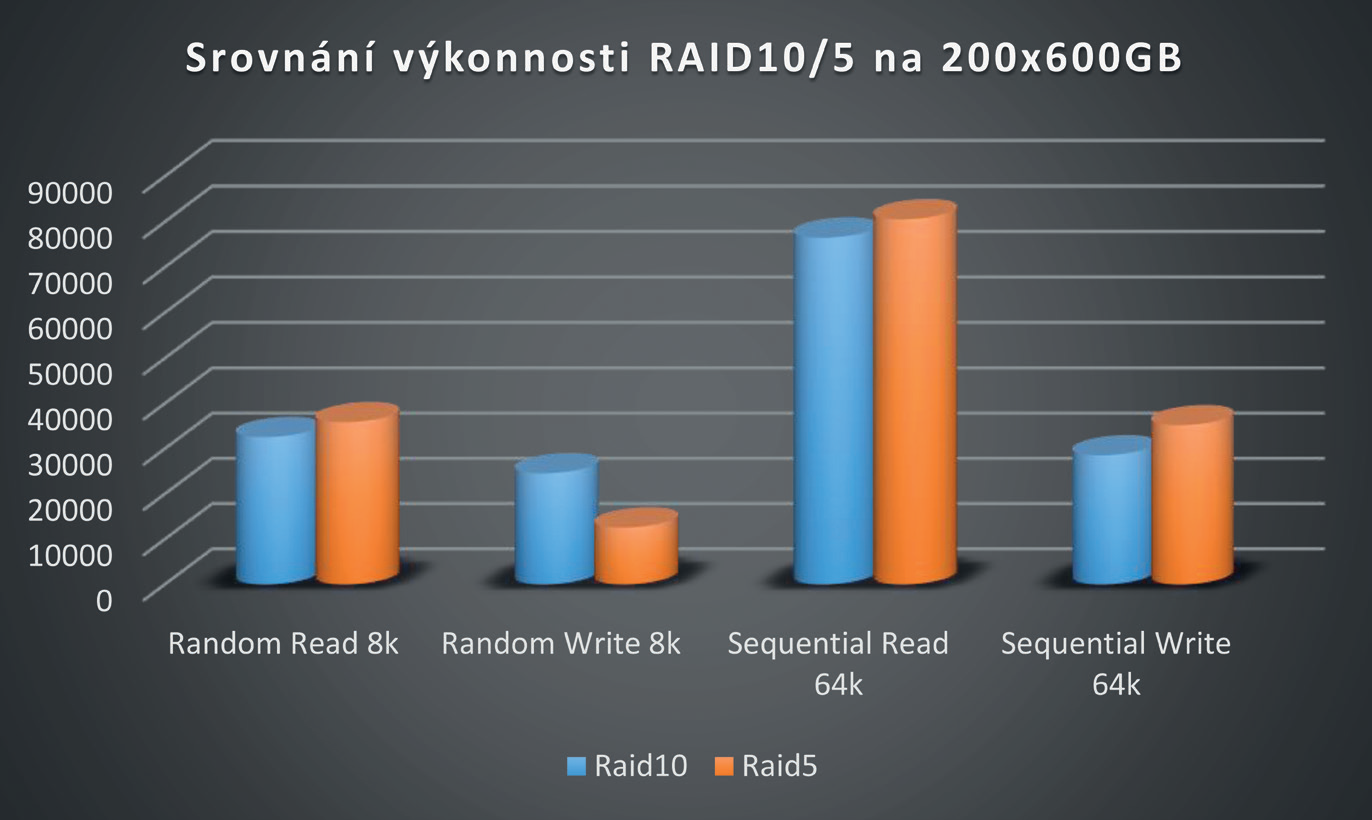
Naměřené výsledky ukázaly, že nejsilnější stránkou RAID 10 jsou zápisy v náhodných operacích. RAID 5 je zase ideální paritní systém pro sekvenční operace.
Proto výrobci databází, jako například Microsoft, ve svých „Best Practicies“ pro SQL jasně uvádějí doporučení pro konfiguraci diskových prostředků. Podstatou této myšlenky je oddělení databázového provozu (který komunikuje typicky v náhodných malých blocích) a redolog provozu (který komunikuje typicky ve velkých write blocích).
Jak je z výše uvedeného grafu vidět, je přímo nasnadě, že pro databáze je ideální RAID 10 a pro redology RAID 5. Oddělení databází a logů má ještě jeden pozitivní dopad – diskovému poli se nad jedním LUN nemíchají dva zcela odlišné typy provozů. Algoritmy cache se pak dokáží efektivněji přizpůsobit a tento aspekt má pozitivní dopad na výkon.
A ZÁVĚREM?
Studie upozornila na obrovský vliv podmínek testu na změřenou výkonnost diskového pole.
Náš modelový příklad s osmi SAS disky měl výkonnostní potenciál v řádu stovek až tisíců transakcí pro náhodné operace. Přesné číslo závisí na typu RAID a skutečnosti, zda jde o čtení či zápis. Oproti tomu sekvenční čtení či zápis dokáže algoritmus diskového pole velmi účinně akcelerovat a rozdíly oproti náhodnému provozu nejsou nikoli ve stovkách procent, ale spíše v tisících procent. Zde bych se vrátil opět k praktické stránce výběru diskového pole z hlediska zadavatele. Jak bylo ukázáno, nastavením podmínek testu lze u té a samé konfigurace dosáhnout – s jistou mírou nadsázky – v podstatě libovolného výsledku.
Pokud zadavatel nechce být zklamán provozními vlastnostmi produktu, který si vybral, je na místě zvážit několik důležitých kroků:
1) Nejlépe analýzou stávajícího prostředí stanovit požadavky na budoucí systém.
2) Vhodným způsobem stanovit typy RAID při respektování best practicies výrobců plánovaných aplikací.
3) Zvážit zda nějaká forma akcelerace pomocí SSD disků (Tiering, Fast Cache) splní očekávání a jejich značný dopad do ceny se opravdu vyplatí.
4) Nadefinovat jakým nástrojem se bude akceptační performance test provádět a jaké budou parametry tohoto testu.
Jakkoli jednotlivé body zní velmi jednoduše, skrývá se za nimi relativně hluboká analýza.
Je k ní nutné rozsáhlé know-how v odboru „storage performance“.
Už jen první krok, tj. analýza stávajícího provozu, skrývá pro storage architekta komplikovaný úkol – musí správně posoudit změřená data. Počet transakcí, které určil monitoring, může mít dva důvody. První možnost je, že aplikace více transakcí negeneruje. Druhá možnost je, že stávající úložný prostředek má výkonnostní limit a prostě více „nepustí“. Toto posouzení je možné na základě analýz latencí a délek front a vyžaduje dostatečné množství zkušeností.
I posouzení vhodnosti nasazení SSD akcelerace je kapitola, která vyžaduje know-how. Prodejce, který tuto znalostní bázi nemá, poznáte podle „recitace“ zjednodušujících marketingových zkratek bez pochopení podstaty problému. Efektivita SSD akcelerace, která spojí výkonnostní potenciál různých médií (SSD, SAS, NL-SAS), je vždy úměrná míře změnovosti dat.
Pokud v objemu uložených dat existují data, která se používají často a naopak „spící“ data, pak i malé množství SSD kapacity významně zvýší výkon, protože diskové pole dokáže rozpoznat, které bloky dat se používají často a ty umístí na nejrychlejší médium.
Nicméně existují i situace a aplikace, které přistupují na všechna uložená data přibližně stejně často. Jinými slovy neexistují tzv. „Hot Data“, které by diskové pole mohlo privilegovat uložením na SSD. V takovýchto případech SSD přinesou jen malé navýšení výkonu, ale zato velké rozčarování z výše učiněné investice.
Posouzení vhodnosti a konfigurace diskového systému tak, aby jeho skutečné nasazení splnilo očekávání, není zcela jednoduchou záležitostí a vyžaduje specialisty.