Odborná sekce
NVMe Hitachi Disková pole E-Series E590 a E790
21.02.2023, 20:01
Virtuální úložné platformy (VSP) E590 a E790 jsou nejnovějšími přírůstky do produktové řady Hitachi pro střední a velké firmy, které jsou navrženy tak, aby využívaly NVMe a poskytovaly špičkový výkon v malém a cenově dostupném provedení. Řada VSP E (která zahrnuje také VSP E990) je optimalizována pro flash paměti, její firmware pracuje na vícejádrových vícevláknových procesorech Intel Xeon. Především díky optimalizacím systému SVOS nabízejí nové modely řady VSP E nejvyšší výkon dostupný v provedení 2U. V tomto blogu se budeme zabývat tím, jak společnost Hitachi vložila špičkový výkon NVMe do velmi malého balení.
Diskové systémy NVMe
Pole řady VSP E využívají protokol NVMe, který byl navržen tak, aby využíval rychlé doby odezvy a paralelních IO schopností paměti flash. NVMe poskytuje zjednodušenou sadu příkazů pro přístup k médiím flash přes sběrnici PCIe nebo úložnou strukturu a umožňuje vytvořit až 64K samostatných front, z nichž každá má hloubku 64K.
Využití plného výkonu paměti flash s protokolem NVMe vyžaduje efektivní operační systém a pokročilé procesory, které jsou součástí nejnovějších polí řady VSP E. Nové technologie obsažené v řadě VSP E doplňuje propracovaná architektura cache optimalizovaná pro flash paměti společnosti Hitachi, která se zaměřuje na integritu dat, efektivitu a optimalizaci výkonu.
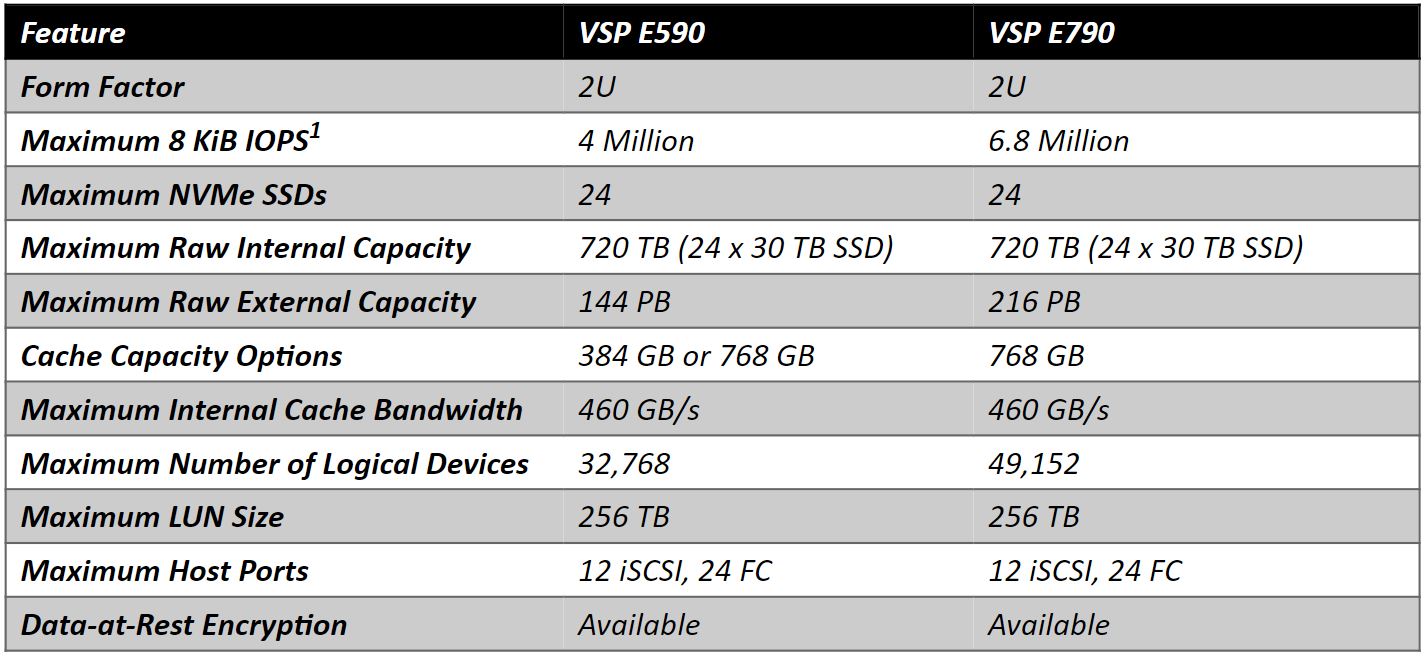
základní specifikace disků VSP E590 a VSP E790.
Hitachi Dynamic Provisioning (HDP)
Hitachi Dynamic Provisioning poskytuje mechanismus pro seskupení mnoha fyzických zařízení (NVMe SSD v řadě VSP E) do jednoho diskového poolu. Mechanismus poolu vytváří strukturu 42 MB stránek z každého zařízení v rámci diskových zdrojů. HDP pak představuje automaticky spravovaná zařízení s širokými bloky jednomu nebo více hostitelům. Jednotky LUN prezentované z poolů HDP se nazývají svazky s dynamickým poskytováním (DPVOL nebo virtuální svazky). DPVOL mají logickou velikost určenou uživatelem až do 256 TB. Hostitel přistupuje k DPVOL, jako by to byl normální svazek (LUN), prostřednictvím jednoho nebo více portů hostitele.

Adaptivní redukce dat (ADR)
Adaptivní redukce dat (Adaptive Data Reduction, ADR) přidává k HDP kompresi a deduplikaci, čímž výrazně zvyšuje efektivní úložnou kapacitu pole. Ke snížení počtu fyzických bitů potřebných k reprezentaci dat zapsaných hostitelem se používá bezeztrátový kompresní algoritmus. Deduplikace odstraňuje nadbytečné kopie identických datových segmentů a nahrazuje je ukazateli na jedinou instanci datového segmentu na disku. Tyto funkce pro úsporu kapacity jsou podporovány ve spojení s HDP, takže disky DPVOL mohou mít povolenou kompresi nebo deduplikaci plus kompresi. (Deduplikace bez komprese není podporována). Každý DPVOL má atribut úspory kapacity, pro který lze nastavit "Zakázáno", "Komprese" nebo "Deduplikace a komprese". Jednotky DPVOL s jedním z nastavených atributů úspory kapacity se označují jako jednotky DRDVOL (Data Reduction Vols).
Mechanismus redukce dat používá kombinaci metod inline a postprocessingu, aby dosáhl úspory kapacity s minimální výkonnostní režií. Po redukci dat je virtuální stránka identifikována jako virtuální stránka DRD a obsahuje pak ukazatele na 8 KB segmenty uložené v různých fyzických stránkách v poolu HDP. Počáteční následné zpracování redukce dat se provádí u virtuálních stránek, které nejsou DRD a u kterých nebyla zaznamenána aktivita zápisu po dobu alespoň pěti minut. Virtuální stránka mimo DRD je zpracována v 8 KB segmentech a komprimovaná data jsou zapsána v logaritmické struktuře na nová místa v poolu, pravděpodobně na jednu nebo více nových fyzických stránek. Pokud je pro DRDVOL povolena deduplikace, provádí se následně deduplikace na komprimovaných segmentech dat, takže duplicitní kousky jsou zneplatněny (po porovnání hash a binárního obsahu) a nahrazeny ukazatelem na umístění fyzického segmentu. Na pozadí se provádí procedura „Garbage collection“, aby se uvolnilo a defragmentovalo volné místo vzniklé zneplatněním datových segmentů. Následné přepisování již komprimovaných dat se pak provádí čistě inline, aby se dosáhlo co nejlepšího výkonu.
Hlavní výhodou přístupu společnosti Hitachi k redukci dat je možnost přizpůsobit nastavení pro každou jednotku LUN. Například kompresi (ale ne deduplikaci) lze nakonfigurovat pro jednotky LUN, na kterých by jedinečné kontrolní součty databáze v každém bloku 8K mohly způsobit, že deduplikace bude méně účinná. Komprese i deduplikace by mohly být povoleny pro jednotky LUN hostující virtuální servery, které mohou obsahovat více kopií stejných dat. A pokud aplikace šifruje nebo komprimuje svá data na hostiteli, což znemožňuje další úspory kapacity, pak lze ADR na dotčených jednotkách LUN zcela zakázat, aby se zabránilo zbytečné režii. Flexibilita řešení ADR společnosti Hitachi umožňuje dosáhnout úspory kapacity u příslušných dat s co nejmenším dopadem na IO operace serverů.
Kontrolery VSP E590 a E790
Základem systému dvou řadičů VSP řady E o velikosti 2U je výpočetní výkon a vysokorychlostní konektivita (jak je znázorněno na následujícím obrázku). Začněme připojením kontroler řadiče diskovým řadičům. Sloty diskových řadičů "A" a "C" se připojují k řadiči prostřednictvím 16 x linek PCIe Gen3, a mají tak k dispozici šířku pásma 32 GB/s (16 GB/s pro odesílání a 16 GB/s pro příjem). Slot "B" dostává osm linek PCIe Gen3, a má tedy teoretickou šířku pásma 16 GB/s. Každý řadič má dva vícejádrové procesory Intel Xeon, propojené dvěma Ultra Path Interconnects (UPI), z nichž každý podporuje až 10,4 gigatransferů za sekundu. Oba procesory pracují jako jedna víceprocesorová jednotka (MPU) na řadič. Stejně jako předchozí generace diskových polí Hitachi pracují všechny procesory řady VSP E s jediným SVOS firmware a sdílejí globální cache. Cache je rozdělena mezi jednotlivé řadiče pro rychlý, efektivní a vyvážený přístup k paměti.
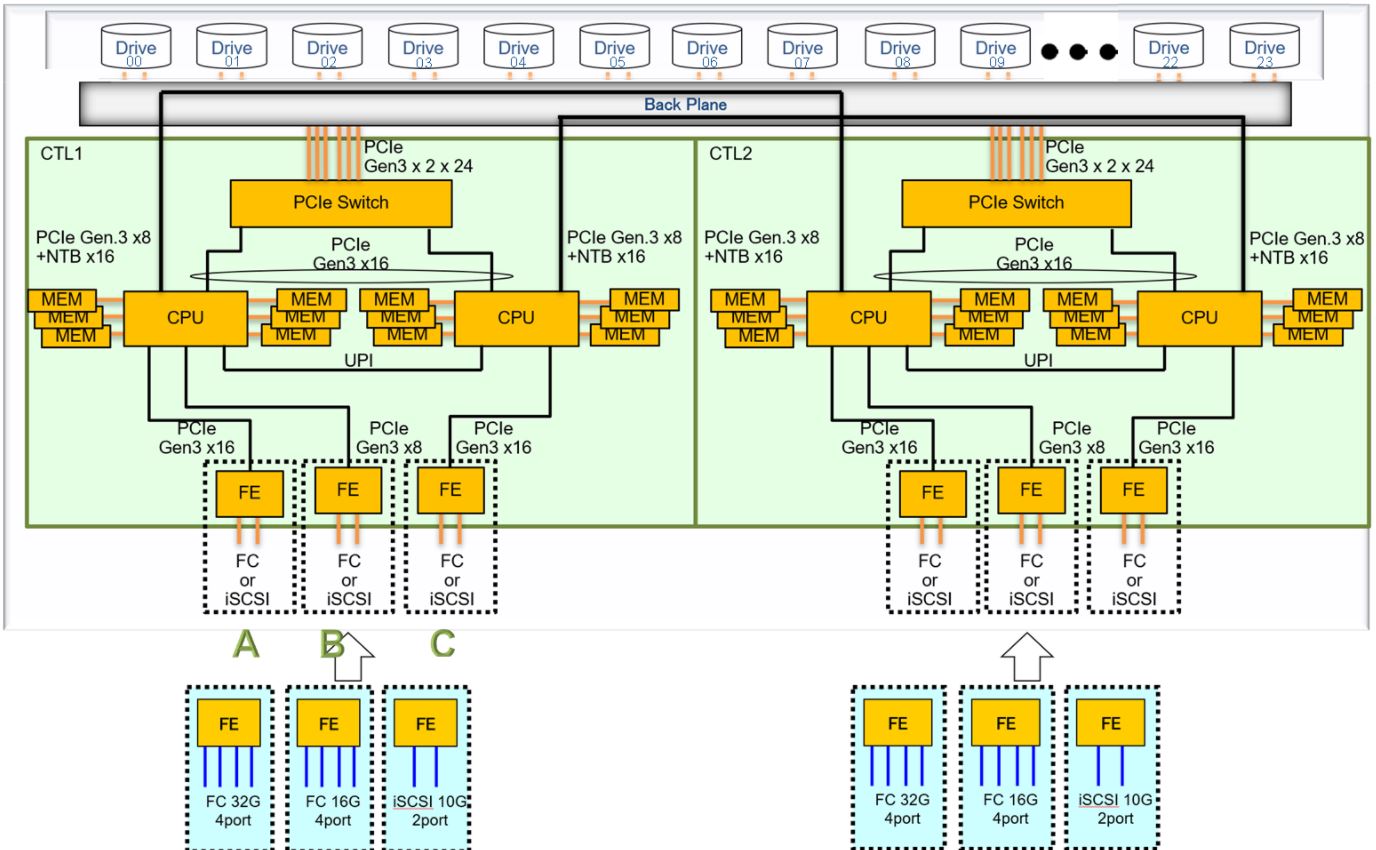
Blokové schéma řadičů VSP E590 a VSP E790
Každý procesor má šest paměťových kanálů pro paměť DDR4, což poskytuje až 115 GB/s na procesor teoretické šířky paměťového pásma (až 230 GB/s na řadič a 460 GB/s na systém). Přenosy dat a příkazů mezi řadiči probíhají přes dvě připojení netransparentní sběrnice (NTB), kterým je dohromady přiděleno celkem 16 x linek PCIe Gen3. Všechna pole řady VSP E jsou vybavena dvěma připojeními NTB mezi řadiči, čímž se zamezuje jakémukoli jedinému bodu selhání této kritické komponenty. A konečně, procesory jednotlivých řadičů jsou připojeny přes vestavěný přepínač PCIe k diskům NVMe SSD. Každý řadič může navázat spojení bod-bod s každým z až dvaceti čtyř disků prostřednictvím 2pásmové sběrnice PCIe Gen3 s rychlostí 4 GB/s.
Hlavním rozdílem mezi VSP E790 a VSP E590 je výpočetní výkon. VSP E790 je vybaven čtyřmi šestnáctijádrovými procesory, zatímco VSP E590 má čtyři šestijádrové procesory. Naše testování ukázalo, že VSP E790 má dostatečný výpočetní výkon, aby se přiblížil plnému potenciálu IOPS rychlých disků NVMe. Například na VSP E790 jsme naměřili 3,64 milionu 8 KiB IOPS při náhodném čtení z osmi SSD disků a s dobou odezvy 0,51 milisekundy. Na diskovém poli VSP E590 bylo ve stejném testu dosaženo 1,34 milionu IOPS s dobou odezvy 0,53 milisekundy. Při stejné konfiguraci disků jako u modelu E590 dokázal model E790 díky výkonným procesorům dosáhnout 2,7× vyššího počtu IOPS. Samozřejmě, že 1,34 milionu IOPS při náhodném čtení u VSP E590 bude pro mnoho aplikací více než dostačující.
Pro VSP E790 a VSP E590 jsou volitelně k dispozici šifrovací řadiče (eCTL). Řadiče eCTL přenášejí práci šifrování na pole programovatelných hradlových polí (FPGA). Řadiče FPGA jsou připojeny pomocí přepínače PCIe umístěného mezi procesory řadičů a jednotkami flash. FPGA umožňují provádět šifrování FIPS 140 úrovně 2 s malým nebo žádným dopadem na výkon.
Architektura Cache
Význam cache úložného se v éře flash disků NVMe možná snížil, nicméně i nadále však cache poskytuje významné zvýšení výkonu, a to z několika důvodů.
Paměť DRAM je rychlejší než paměť flash, přinejmenším o řád. Když server požaduje data umístěná v cache (někdy se tomu říká "cache hit“), může být příkaz dokončen s nejnižší možnou latencí. Například při našem testování náhodného zásahu při čtení 8KiB na VSP E590 byla naměřena doba odezvy pouhých 66 mikrosekund (0,066 milisekundy !). Nejrychlejší doba odezvy zjištěná při testování náhodného čtení 8 KiB byla přibližně 4x vyšší a činila 250 mikrosekund. Čtení dat z mezipaměti je výhodné nejen proto, že DRAM je nejrychlejší médium, ale také znamená, že požadavek na data je uspokojen bez dalšího vyhledávání adres nebo backend I/O příkazů.
A pokud jde o optimalizaci výkonu, společnost Hitachi se nespokojuje s pouhým ukládáním naposledy přístupných dat do mezipaměti. Vzorce IO operací na každém LUNu jsou pravidelně analyzovány, aby bylo možné identifikovat data, u nichž je nejpravděpodobnější, že k nim bude přistupováno opakovaně. Takovým blokům je přednostně přidělována mezipaměť. Mezitím oblasti každého LUN identifikované jako oblasti s nejnižší pravděpodobností zásahu do cache nebudou mít alokovanou žádnou cache. Místo toho jsou taková data odesílána hostiteli přímo z disku prostřednictvím přenosové vyrovnávací paměti, čímž se ušetří režie spojená s přidělením segmentu globální cache.
Cache také zvyšuje výkon zápisu. Po zrcadlení zápisů v paměti DRAM obou řadičů kvůli ochraně před ztrátou dat (avšak před zápisem dat do paměti flash) je hostiteli zasláno potvrzení o zápisu. Rychlá odezva na zápis umožňuje bezproblémový provoz aplikací citlivých na latenci. Nově zapsaná data jsou po určitou dobu držena v mezipaměti, aby bylo možné související bloky agregovat a zapsat do paměti flash společně ve větších celcích. Tento algoritmus "shromažďování zápisu" snižuje potřebu paritních operací, čímž snižuje vytíženost řadiče a zlepšuje celková doba odezvy (agragace zápisů snižuje takzvanou RAID Write Penaltu).
Srovnání s konkurencí
Použití disků typu NVMe či v budoucnu ještě rychlejších SCM (Stora class memory) postavilo výrobce diskových systémů před zcela nové výzvy, které znamenají nutnost zcela odlišného přístupu k tvorbě mikrokódu. Řada výrobců tento fakt podcenila, aby mohli dodávat NVMe disková pole mezi prvními, aniž by provedli nezbytné změny v architektuře diskových kontrolerů.
Například špičkový specialista v oboru "Data Storage", Marc Staimer již v minulosti blogoval o tom, jak problémy s výkonem NVMe diskových polí odhalují jako úzké hrdlo CPU. Někteří prodejci se to pokusili vyřešit přidáním dalších procesorů. To však přidává další komplexnost a náklady. Společnost Hitachi se rozhodla optimalizovat architekturu úložiště před implementací NVMe, aby získala maximální benefit z nových výkonnostních schopností NVMe. Parametry co do kategorie obdobných systémů můžete srovnat v následujcí tabulce.
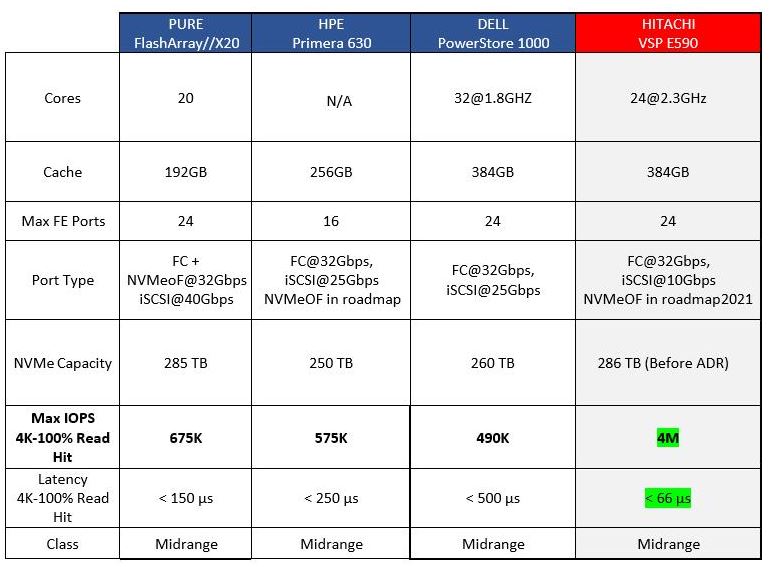
Reference
Společnost 3S.cz je největším autorizovaným prodejním a servisním partnerem v České republice. Těchto vysoce výkonných a robustních systémů Hitachi jsme v české republice realizovali řadu instalací s úhrnnou klapacitou přesahující 100PB!. Podrobnosti zde.
Zajišťujeme komplexní návrhy systémů úschovy elektronických dat s ohledem na bezpečnost a efektivitu jejich správy. Řešení jsme již navrhli pro desítky významných zákazníků, ať se jednalo o komplexní robustní řešení nebo přiměřená řešení pro uživatele s nižšími nároky. Specializujeme se na širokou oblast storage řešení – od primárního úložiště, zálohování a archivaci dat až po management software. Poskytujeme nejen on premise řešení, ale i hybridní či privátní cloudy nebo cloud jako službu.